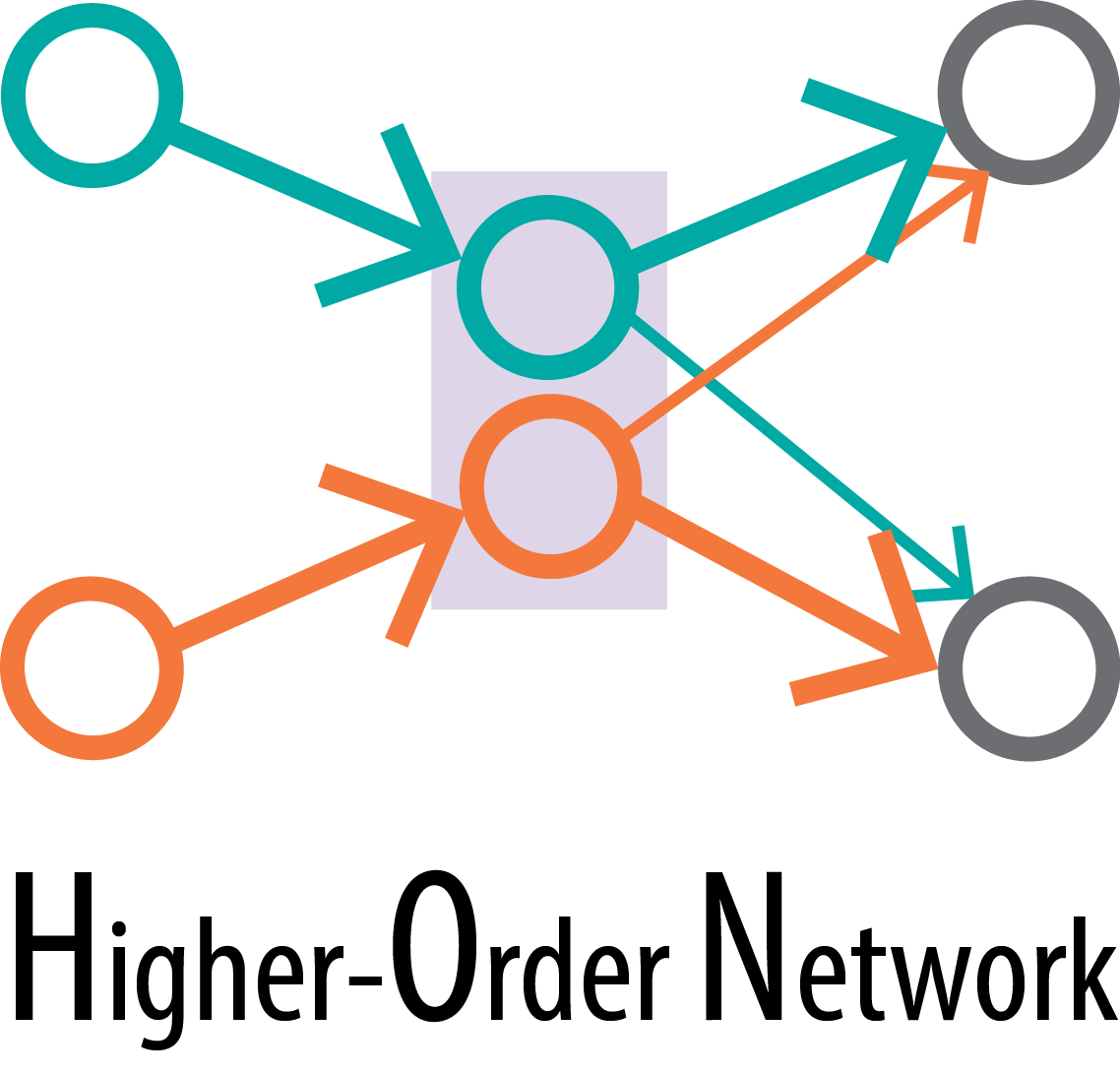
Dynamic processes on networks
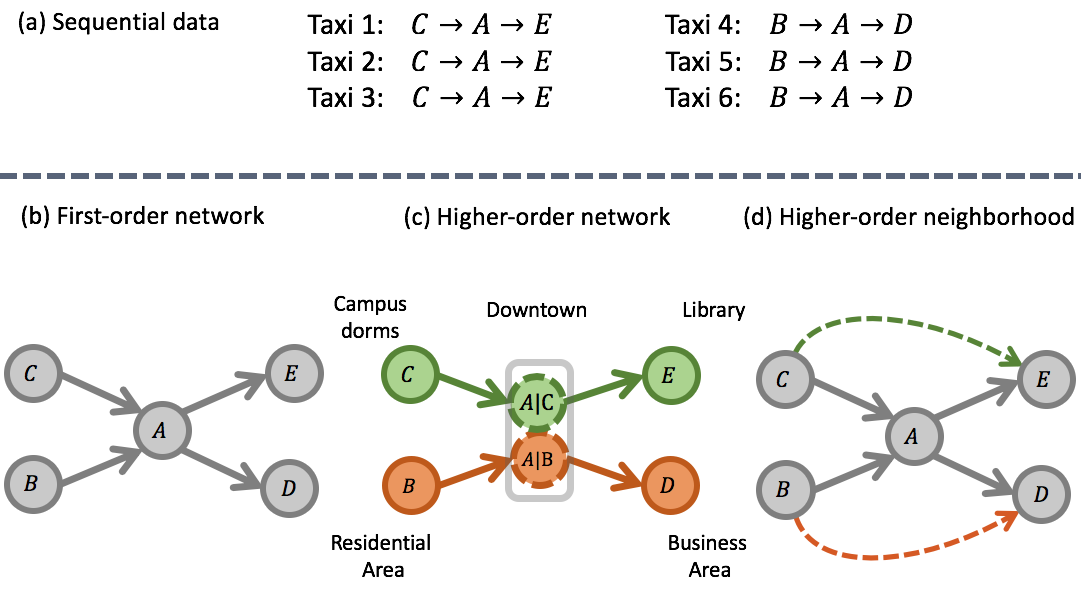
Suppose we have these ship trajectories, the first two ships are going back and forth between port A and port B. The third ship goes between port A and port C. We can construct both the first-order network and the higher-order network from these trajectories.
Then based on the network structure, we predict where the ship is going. On the first-order network, if a ship used to go between a and b, it is not guaranteed to go back to b again. But on the higher-order network, if a ship goes from b to a, according to the network structure, it will go back to b for sure.
We can compare the predicted trajectories with the testing set, and know how accurately movements are simulated on these two networks. If we use HON, the accuracy is doubled compared with the first order network when simulating the next step. In comparison, the fixed 2nd order network is not as accurate as HON, but the network size is already larger than that of HON. When simulating multiple steps (for example, PageRank can be seen as implicit random walkers with multiple steps), the advantage of HON is even larger.
Note that we are not attempting to perform "next step prediction"; rather, the accuracies for simulating the next step(s) is a measurement of the quality of representation, in terms of how well the network can help reproduce the true movement patterns in the raw data.
Clustering
For the control of species invasion through the global shipping network
The estimated damage and control costs of invasive species in the US are $120 billion per year, which is an invisible tax that everyone has to pay. One of the major vectors of species introduction is through global shipping; species may be taken up with ballast water at one location, and discharged at another.
The question is: can we discover the species flow patterns by studying the global shipping network, in order to inform the policy makers to devise effective invasive species control policies?
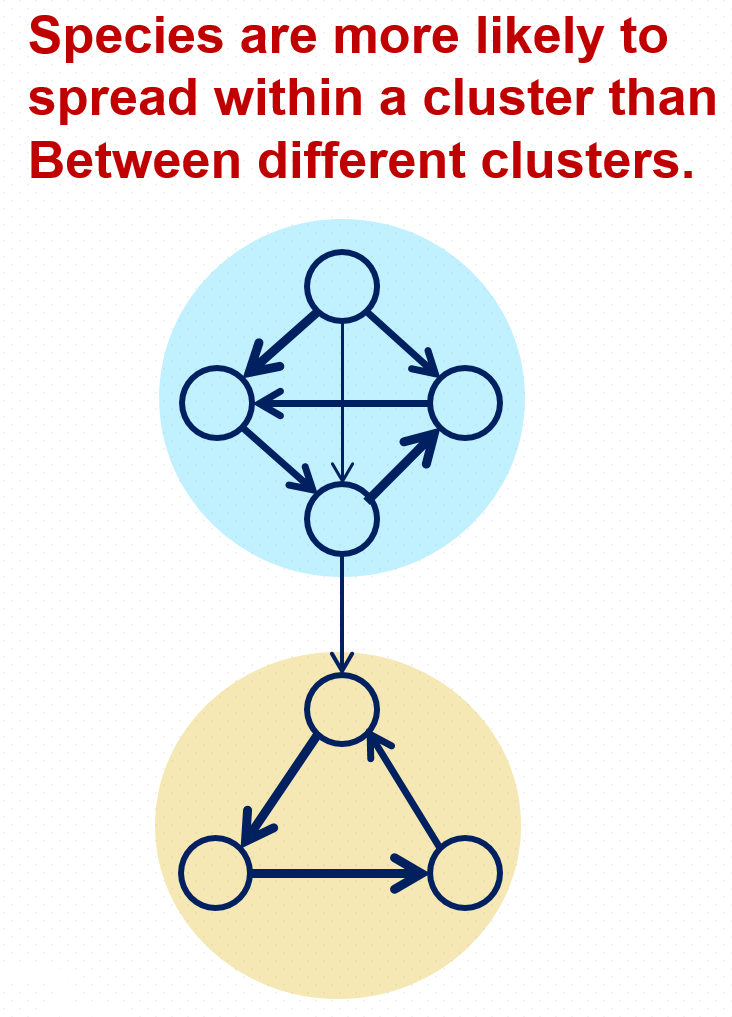
Clustering methods based on flow dynamics, such as Infomap [Rosvall et al.] and Walktrap [Pons], can help us identify clusters of ports that are loosely connected to each other by shipping traffic. Controlling the connections between clusters can prevent species propagation from one cluster of ports to another.
If we do clustering on the first-order network, the nodes shown appear to be equivalent. In reality, given ship movements, species are potentially more likely to be introduced to Los Angeles indirectly from Shanghai. Clustering on HON will automatically take this into account and cluster Tokyo and Seattle together.
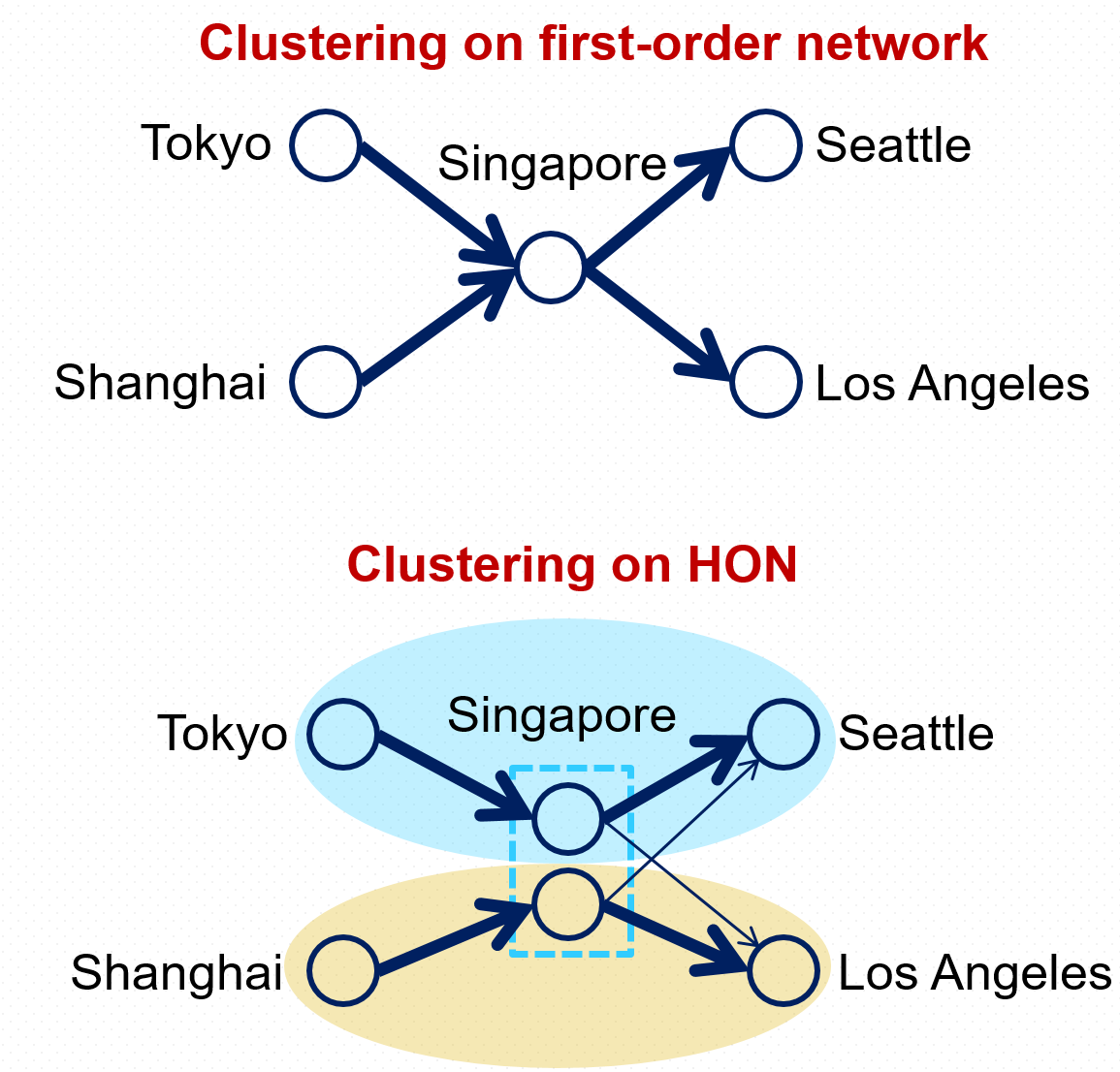
Clustering on first-order network
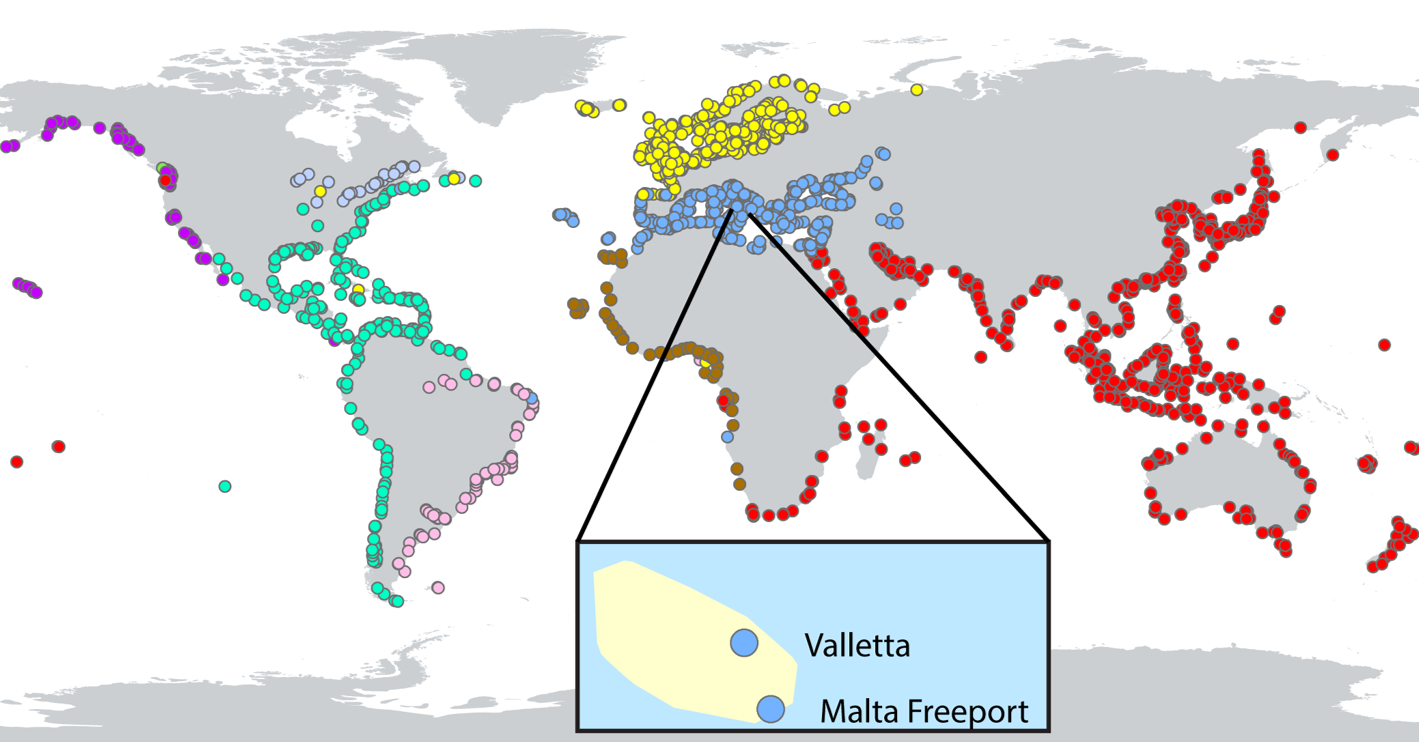
If we cluster the ports on the first-order network, it shows reasonable results, where different colors represent different clusters. Ports geographically close to each other are likely to bring invasive species to each other.
We see that for Malta, a small country in the Mediterranean, these two ports belong to the same Mediterranean cluster.
Clustering on HON
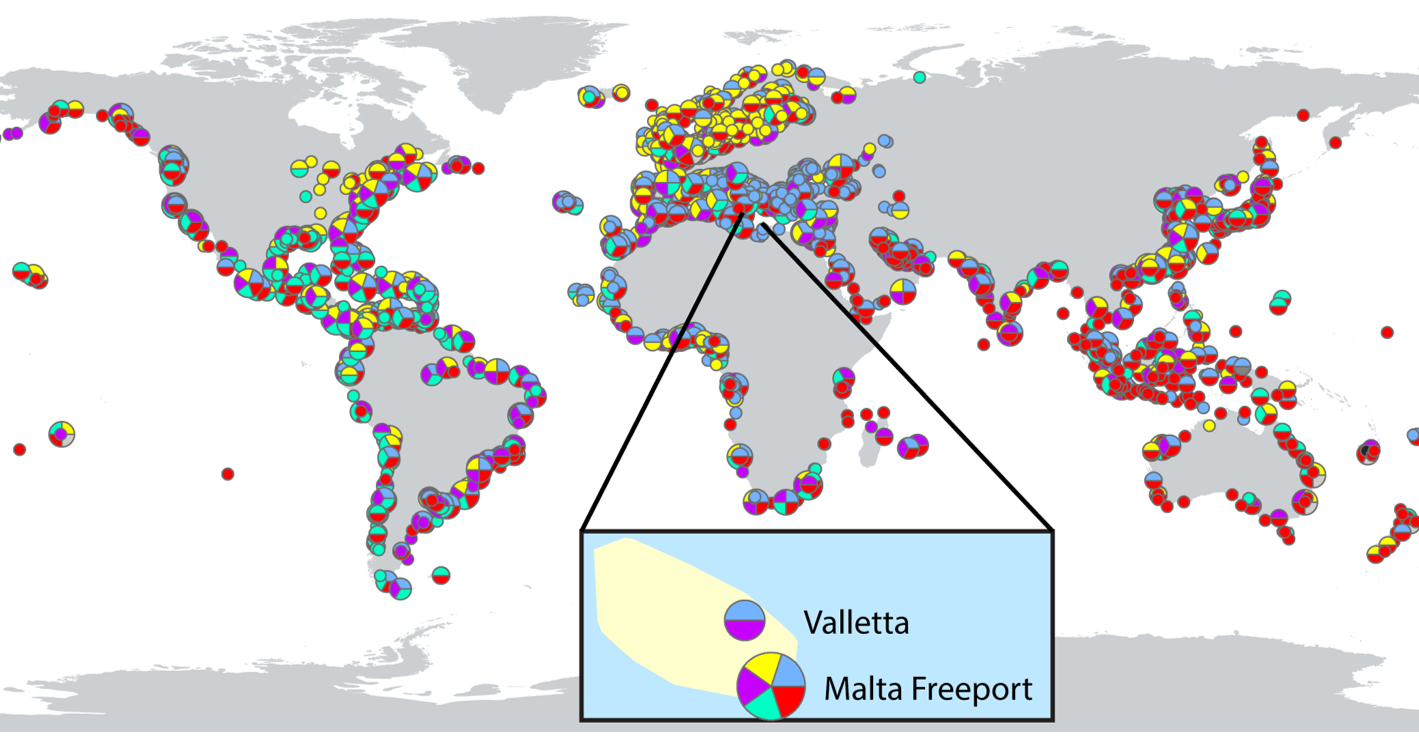
On the higher-order network, however, clustering shows that Malta Freeport belongs to as many as five clusters, very different from Valletta, even they are geographically close to each other. The reason is that Valletta is a small local port, while Malta Freeport is an international port, with lots of traffic and is potentially susceptible to multiple sources of invasions.
Clustering on HON is able to reflect such differences, with no changes to the clustering algorithm itself. The ability to capture indirect species invasions is critical for devising effective species control policies.
Ranking
For modeling Web surfing behavior
Given the same clickstreams of Web pages, one could build a first-order network as shown. According to the network structure, after a user views or uploads a photo, the user is very likely to go back to the home page.
The higher-order network representation of the same data, however, shows additional information. It keeps the nodes and connections of the first-order network, but in addition, it adds to other higher-order nodes, representing the natural scenario that once a user uploads and views a photo, the user is very likely to keep uploading more photos rather than going back to the home page.
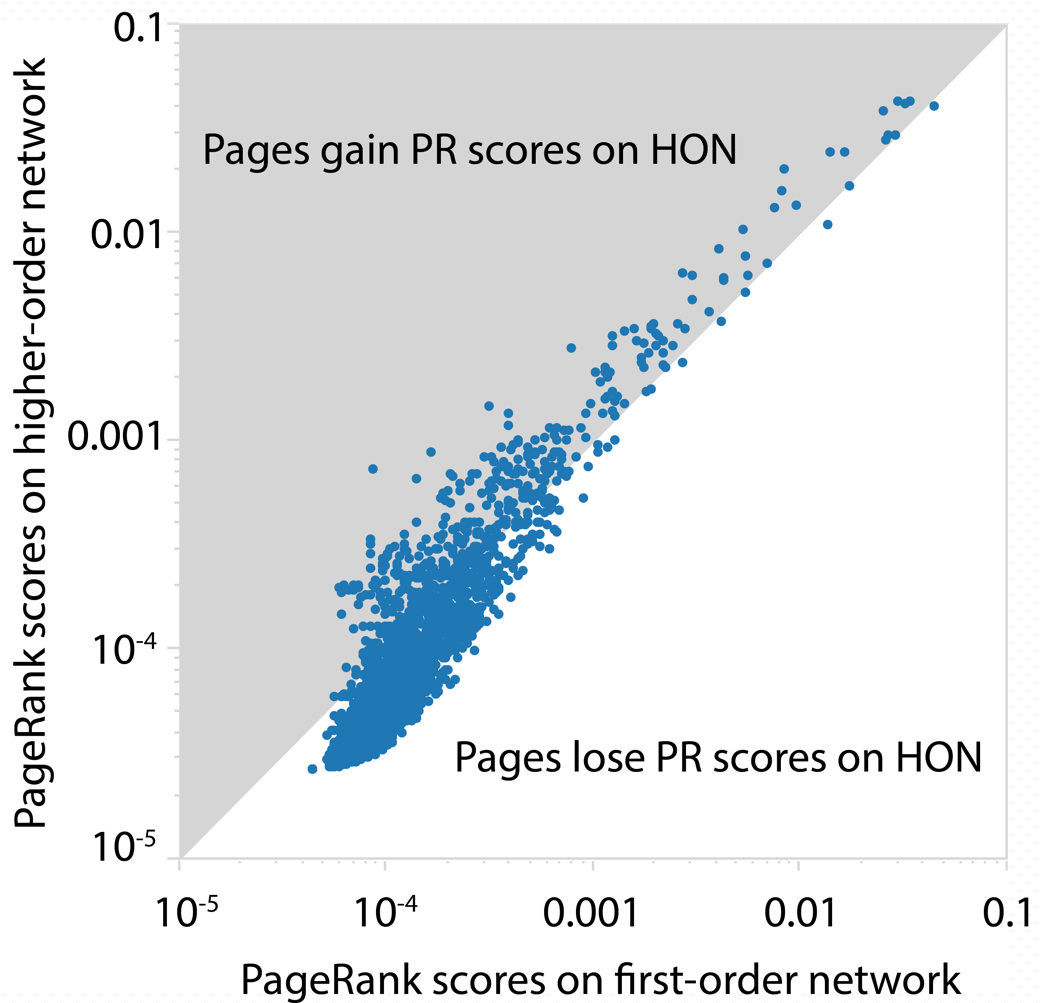
Given that PageRank is essentially random walks with resets on a network, the random walker is more likely to get trapped in the strong loop in HON, leading to differences in PR scores. More than 90% pages lose PageRank scores, while a few pages gain significant scores.
In the raw data, we see weather forecast and obituaries gain the most scores on HON, which is natural considering the data set is from a news company. By using the HON, PageRank is able to simulate complex user browsing behaviors, with no changes to the PageRank algorithm.
Network Representation Learning
For node classification, link prediction, and visualization
We prsent HONEM, a higher-order network embedding method that captures the non-Markovian higher-order dependencies in a network.
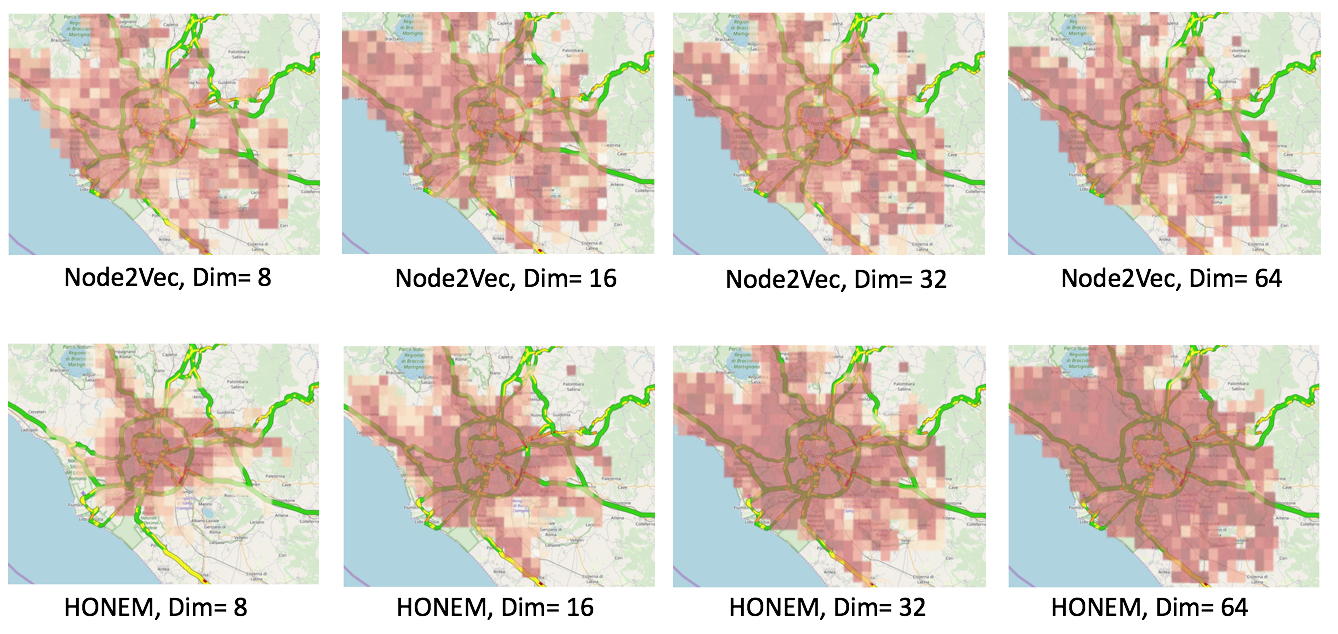
We evaluate HONEM on the node classification task on traffic data of Rome and Bari. We realized that representation learning based on the HON structure provides higher node classification accuracy for the nodes, especially the ones with high traffic. We visualized the node precision using HONEM and Node2Vec (based on FON) over various dimensions on the Rome city map. We realize that nodes with the highest precision (darker color) are located in the high-traffic city zones (green lines show the major highways of the city). Based on our analysis, nodes located in the high-traffic zones are 80.56% more likely to have a dependency of second -order or more. As a result, in lower dimensions, HONEM consistently exhibits high precision for these higher-order nodes. As the dimension increase, the precision of the lower-order nodes also increases. On the other hand, node precision obtained by Node2Vec is not related to the node location. In dim=32 and dim=64, HONEM provides an overall better coverage and better precision than Node2Vec.
Anomaly detection
For the control of species invasion through the global shipping network
Existing approaches use the first-order network (FON) to represent the underlying raw data, which may lose important higher-order sequence patterns, making higher-order anomalies undetectable in subsequent analysis.
By replacing FON with higher-order network (HONs), we show that existing anomaly detection algorithms can better capture higher-order anomalies that may otherwise be ignored.
We show that the existing HON construction algorithm cannot be used for the anomaly detection task due to the extra parameters and poor scalability; we introduce a parameter-free algorithm that constructs HON in big data sets.
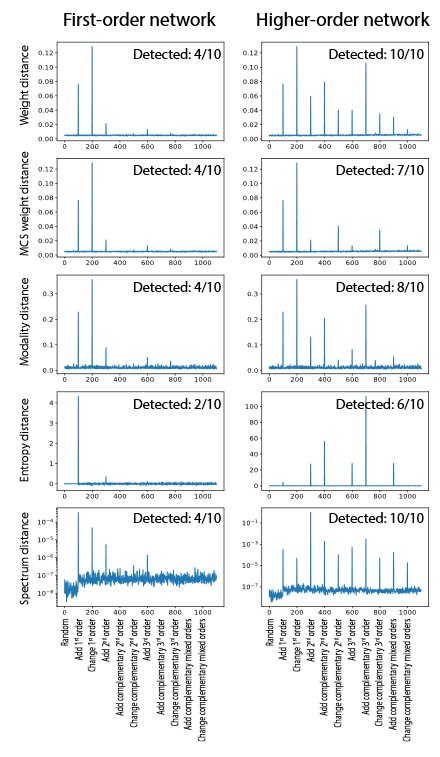
Using a large-scale synthetic data set with 11 billion web clickstreams, we demonstrate how the proposed method can capture variable orders of anomalies.
Using a real-world taxi trajectory data, we show how the proposed method amplifies higher-order anomaly signals.
And more applications
